 |
Das deutsche QBasic- und FreeBASIC-Forum
Für euch erreichbar unter qb-forum.de, fb-forum.de und freebasic-forum.de!
|
| Vorheriges Thema anzeigen :: Nächstes Thema anzeigen |
| Autor |
Nachricht |
Input
Anmeldungsdatum: 28.07.2014
Beiträge: 59
|
 Verfasst am: 17.08.2014, 16:06 Titel: Verfasst am: 17.08.2014, 16:06 Titel: |
 |
|
Hallo liebes Forum, hab da noch ein Problem: Ich würde gern jedes Wort im Text zählen, weiss aber nicht ob mein Algi für die einzelnen Wörter als "Input" so gut ist. Wäre froh um jeden Tipp, Komplettlösung wär natürlich auch nicht schlecht. Vielen Dank!!
| Code: |
dim as integer k,l,m
dim as string suche,text
Open "Finden.txt" For Binary Access Read As #1
line input #1,text
do
for k=0 to 5
if mid(text,l,k)=space(1) then
for m=2 to 5
suche=mid(text,l,m)
if mid(suche,m,1)=space(1) then suche=ucase(rtrim(suche)):print suche
next m
end if
next k
l=l+1
loop until l=len(text)
|
|
|
| Nach oben |
|
 |
Sebastian
Administrator

Anmeldungsdatum: 10.09.2004
Beiträge: 5969
Wohnort: Deutschland
|
| Verfasst am: 17.08.2014, 17:56 Titel: Wörter zählen und Durchschnittslänge ermitteln |
|
|
Hallo,
was hältst du von folgendem Code? Er zählt die Wörter und ermittelt nebenbei die durchschnittliche Länge eines Wortes. 
| Code: | Declare Function isSplittingChar (char As UByte) As Integer
Enum EState
undefined
word
End Enum
Dim As UByte char
Dim As EState state = EState.undefined
Dim As UInteger numWords = 0
Dim As UInteger currentWordCharCount = 0, totalCharCount = 0
Open ExePath + "/testtext.txt" For Binary As #1
Do Until Eof(1)
Get #1, , char
If (isSplittingChar(char)) Then
If (state = EState.word) Then
numWords += 1
totalCharCount += currentWordCharCount
currentWordCharCount = 0
state = EState.undefined
End If
Else
If (state = EState.undefined) Then
state = EState.word
currentWordCharCount = 0
End If
currentWordCharCount += 1
End If
Loop
'Ist noch ein Wort angefangen?
If (state = EState.word) Then
numWords += 1
totalCharCount += currentWordCharCount
End If
Close #1
Dim As Double averageLength = 0
If (numWords > 0) Then
averageLength = (totalCharCount / CDbl(numWords))
End If
Print "Es wurden " & numWords & " Woerter gezaehlt."
Print "Die durchschnittliche Wortlaenge betrug ";
Print Using "##.## "; averageLength;
Print "Buchstaben."
Print
Print "Druecken Sie eine beliebige Taste zum Beenden."
GetKey
End 0
'Ermittelt, ob das uebergebene Zeichen eines ist, das das Ende
'eines Wortes kennzeichnet (zum Beispiel ein Leerzeichen, ein
'Zeilenumbruch oder ein Komma).
Function isSplittingChar (char As UByte) As Integer
' , . : ; /
Return ((char < 33) Or (char = 44) Or (char = 46) Or (char = 58) Or (char = 59) Or (char = 47))
End Function |
Als Beispiel wird diese Datei verwendet:
| Code: | Schiller: Das Lied von der Glocke
Fest gemauert in der Erden
Steht die Form, aus Lehm gebrannt.
Heute muß die Glocke werden.
Frisch Gesellen, seid zur Hand.
Von der Stirne heiß
Rinnen muß der Schweiß,
Soll das Werk den Meister loben!
Doch der Segen kommt von oben.
Ende |
Das führt zur Ausgabe:
| Code: | Es wurden 48 Woerter gezaehlt.
Die durchschnittliche Wortlaenge betrug 4.46 Buchstaben.
Druecken Sie eine beliebige Taste zum Beenden. |
Der Code liest die Datei Zeichen für Zeichen ein und kann dabei zwischen 2 Zuständen wechseln: "Wort" und "Irgendwas anderes". Auf diese Weise führen vielfache Leerzeichen, Kommas o. ä. nicht dazu, dass die Wortzahl zu hoch ermittelt wird. Nur beim Wechsel zwischen "Wort" und "Irgendwas anderes" wird der Wortzähler erhöht (oder am Ende der Datei, falls noch ein angefangenes Wort aktiv ist). Das könnte man auch schön als Automat modellieren.
In der Funktion isSplittingChar kann flexibel konfiguriert werden, welche Zeichen das Ende eines Wortes signalisieren sollen. So könnte man beispielsweise leicht noch Fragezeichen, Ausrufezeichen o. ä. hinzufügen, während z. B. ein Bindestrich kein neues Wort einleiten soll. Ob "Müller-Lüdenscheid" als 1 oder 2 Wörter zählen soll, kann man so anpassen.
Viele Grüße!
Sebastian
_________________

Die gefährlichsten Familienclans | Opas Leistung muss sich wieder lohnen - für 6 bis 10 Generationen! |
|
| Nach oben |
|
|
Input
Anmeldungsdatum: 28.07.2014
Beiträge: 59
|
| Verfasst am: 17.08.2014, 19:14 Titel: |
|
|
Vielen Dank!! Ich möchte aber eigentlich nur das erste Wort als Variable in ein Arrey schreiben, dann das Zweite...
Wenn dann ein Wort im Arrey schon vorhanden ist, dann wird einfach die Zahl auf 2 erhöht. Am Ende sollte es dann etwa so aussehen: Und=3 das=5 Hase=1
Mein Problem ist jetzt einfach, dass mein Prog sehr langsam ist und die Schleife wohl fast unendlich dreht. |
|
| Nach oben |
|
|
Sebastian
Administrator
Anmeldungsdatum: 10.09.2004
Beiträge: 5969
Wohnort: Deutschland
|
| Verfasst am: 17.08.2014, 19:39 Titel: HashMap / Baum |
|
|
Hallo,
dann bräuchtest du idealerweise sowas:
http://de.wikipedia.org/wiki/Hashtabelle
Wenn du ein Wort isoliert hast, musst du vom Wort (= String) zu einer Integer-Variablen kommen, die diesem Wort zugeordnet ist. Diese Integer-Variable wäre der Häufigkeitszähler des Wortes.
Eine relativ schlichte Lösung bestünde darin, einen TYPE anzulegen, der ein Wort und einen Integer enthält, und davon ein Array zu erzeugen:
| Code: | TYPE TWordOccurrences
Word As String
Occurrences As Integer
END TYPE
Dim WordLookupArray(1 To 1) As TWordOccurrences |
Dieses Array müsste für jedes gefundene Wort von Anfang bis Ende durchlaufen werden. Wenn ein gleichlautendes Wort im Array gefunden wird, wird der Zähler erhöht. Ansonsten müsste das Array mit Redim Preserve vergrößert werden. Der neu hinzugefügte Datensatz müsste mit dem Zähler 1 initialisiert werden.
Das wäre allerdings gleich an verschiedenen Stellen ineffizient. Arrays können eigentlich nicht wachsen. Müssen sie vergrößert werden, wird ein neues, größeres Array erzeugt und das alte (kleine) Array wird in das neue (große) rüberkopiert. Außerdem muss für jedes Wort in der Datei das zunehmend größere Array sequentiell durchsucht werden. Für jede Array-Zeile muss ein aufwendiger String-Vergleich durchgeführt werden. Insgesamt wäre das relativ langsam - ganz besonders, wenn die Input-Datei groß ist und nicht bloß 48 Wörter enthält.
Eine HashMap o. ä. bietet FreeBASIC leider nicht von Haus aus an. Es gibt, wenn ich mich recht erinnere, Map-Implementierungen von Stueber und von MOD (mdTypes). Wie sich die performancemäßig machen, weiß ich spontan aber leider nicht mehr.
Eine Möglichkeit für eine eigene Implementierung könnte ein Baum sein. Jeder Knoten hätte (wenn die Groß-/Kleinschreibung egal wäre) 26 Sub-Knoten (= Pointer) und einen Integer-Datenwert. Dieser entspräche der Häufigkeit des Buchstabenpfads, der in diesem Knoten endet. Die Tiefe des Baums entspräche der maximalen Wortlänge. Dieser Ansatz käme ohne eine Hash-Funktion aus.
Viele Grüße!
Sebastian
_________________
Die gefährlichsten Familienclans | Opas Leistung muss sich wieder lohnen - für 6 bis 10 Generationen! |
|
| Nach oben |
|
|
grindstone
Anmeldungsdatum: 03.10.2010
Beiträge: 1211
Wohnort: Ruhrpott
|
| Verfasst am: 18.08.2014, 09:37 Titel: |
|
|
Hallo,
| Input hat Folgendes geschrieben: | | Komplettlösung wär natürlich auch nicht schlecht. |
Bitte sehr, für dich tun wir doch alles!  Ich habe unter Verwendung von Sebastians Trennzeichen-Function ein Programm geschrieben, das mit sukzessiver Approximation arbeitet. Das ist schneller als eine lineare Suche und einfacher als das Hashverfahren. Ich habe unter Verwendung von Sebastians Trennzeichen-Function ein Programm geschrieben, das mit sukzessiver Approximation arbeitet. Das ist schneller als eine lineare Suche und einfacher als das Hashverfahren.
Du hast dabei eine (alphabetisch) geordnete Tabelle aller bisher gefundenen Wörter. Um ein bestimmtes Wort zu suchen, fängst du in der Mitte der Tabelle an und prüfst, ob das Wort an dieser Stelle vor oder hinter dem gesuchten Wort steht, das Wort also in der oberen oder der unteren Hälfte der Tabelle zu suchen ist. Diese Hälfte teilst du wieder in zwei Hälften usw., wobei du die Schrittweite jedesmal halbierst. Damit lässt sich eine Tabelle mit 2^n Elementen mit n Schritten durchsuchen.
Die Länge des Arrays sollte eine Zweierpotenz sein (also 16, 32, 64 usw), deshalb wird seine Größe jedesmal verdoppelt, wenn es zu klein wird. | Code: | Declare Function isSplittingChar (char As UByte) As Integer
Type wa
wort As String
anzahl As Integer
End Type
ReDim As wa tabelle(16)
Dim As String text
Dim As Integer anfang, ende, x, schrittweite
Open ExePath + "/testtext.txt" For Binary Access Read As #1
text = Input (Lof(1),1) 'datei einlesen
Close 1
anfang = -1
Do 'text abarbeiten
Do 'nächsten wortanfang suchen
anfang += 1
Loop Until (isSplittingChar(text[anfang]) = 0) Or (anfang > Len(text))
ende = anfang
Do 'nächstes wortende suchen
ende += 1
Loop Until (isSplittingChar(text[ende]) <> 0) Or (ende >= Len(text))
tabelle(0).wort = LCase(Mid(text,anfang + 1, ende - anfang)) 'wort aus text holen
If tabelle(0).wort = "" Then
Exit Do
EndIf
anfang = ende 'zeiger für nächste suche setzen
x = UBound(tabelle) / 2 'mitte der tabelle
schrittweite = x / 2
tabelle(0).anzahl = 1 'zählerwert für neues wort
Do 'wort in tabelle suchen
If tabelle(x).wort = tabelle(0).wort Then 'wort gefunden
Exit Do
ElseIf tabelle(x).wort > tabelle(0).wort Or tabelle(x).wort = "" Then
x -= schrittweite 'nach oben
ElseIf tabelle(x).wort < tabelle(0).wort Then
x += schrittweite 'nach unten
EndIf
schrittweite /= 2 'schrittweite halbieren
Loop While schrittweite >= 1
If tabelle(x).wort = tabelle(0).wort Then 'wort schon vorhanden
tabelle(x).anzahl += 1 'zähler erhöhen
Else 'neues wort einfügen
Do While (tabelle(x).wort < tabelle(0).wort) And (tabelle(x).wort <> "") 'index korrigieren
x += 1
Loop
Do 'alle werte hinter dem neuen wort um eine stelle nach unten schieben
Swap tabelle(x),tabelle(0)
x += 1
Loop Until tabelle(0).wort = ""
If tabelle(UBound(tabelle)).wort <> "" Then
ReDim Preserve tabelle(UBound(tabelle) * 2) 'tabellengröße verdoppeln
EndIf
EndIf
Loop Until ende >= Len(text)
For x = 1 To UBound(tabelle)
If tabelle(x).wort = "" Then
Exit For
EndIf
Print x;" ";tabelle(x).wort;" =";tabelle(x).anzahl
If x Mod 20 = 0 Then
Sleep
EndIf
Next
Sleep
End
'Ermittelt, ob das uebergebene Zeichen eines ist, das das Ende
'eines Wortes kennzeichnet (zum Beispiel ein Leerzeichen, ein
'Zeilenumbruch oder ein Komma).
Function isSplittingChar (char As UByte) As Integer
' , . : ; /
Return ((char < 33) Or (char = 44) Or (char = 46) Or (char = 58) Or (char = 59) Or (char = 47))
End Function |
Gruß
grindstone
_________________
For ein halbes Jahr wuste ich nich mahl wie man Proggramira schreibt. Jetzt bin ich einen! |
|
| Nach oben |
|
|
Sebastian
Administrator
Anmeldungsdatum: 10.09.2004
Beiträge: 5969
Wohnort: Deutschland
|
| Verfasst am: 18.08.2014, 16:09 Titel: Implementierung mit Baum |
|
|
Hallo,
ich habe mal den Ansatz mit einem Baum implementiert:
http://users.freebasic-portal.de/sebastian/fb/wordcount/wordcount_tree.zip
Hier der Quelltext (ist aber auch im ZIP-Archiv enthalten):
http://users.freebasic-portal.de/sebastian/fb/wordcount/wordcount_tree.bas
Das ZIP-Archiv enthält die rund 1 MB große deutsche Übersetzung der Debian-Referenz.
Das Programm ist nur oberflächlich getestet. Verwendung auf eigene Gefahr und ohne Garantie für Richtigkeit der Ergebnisse. Sicherlich sind an manchen Stellen Optimierungen möglich. Zum Beispiel wird oft LEN(...) ermittelt. Das könnte man besser als Integer-Parameter mitschleifen, damit das nicht so oft ermittelt werden muss. Allerdings wird dadurch das Programm auch etwas unübersichtlicher.
Der Häufigkeitsbaum wird so tief wie die Länge des längsten Wortes. Der Aufwand zum Nachschlagen einer Worthäufigkeit ist linear von der Wortlänge abhängig und dauert für alle Worte der Länge n gleich lang (Best Case = Worst Case = Average Case). Es ist also etwas anderes als eine sequentielle "Liste", wo es eine Rolle spielt, ob das Wort am Anfang der Liste sofort gefunden wird (Best Case) oder erst die ganze Liste bis zum Ende durchsucht werden muss, ehe das Wort gefunden wird (Worst Case).
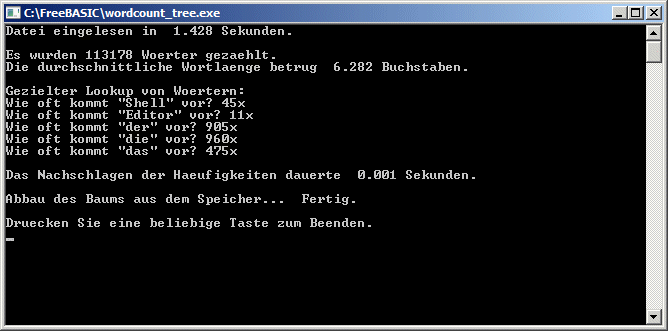
Bei den Zeitmessungen ist zu beachten, dass beide durch PRINT-Ausgaben zwischendurch verfälscht (= verlängert) werden (Zeilen 64-66 und Zeile 107).
Viele Grüße!
Sebastian
_________________
Die gefährlichsten Familienclans | Opas Leistung muss sich wieder lohnen - für 6 bis 10 Generationen! |
|
| Nach oben |
|
|
Input
Anmeldungsdatum: 28.07.2014
Beiträge: 59
|
| Verfasst am: 18.08.2014, 21:40 Titel: |
|
|
Vielen Dank euch beiden; ihr seit ja echte Freaks!!  Ich werd es aber trotzdem mal selber noch versuchen; vom Prinzip her sollte es ja nicht all zu schwer sein. Werde mich melden, wenn ich's geschafft hab. LG: Input Ich werd es aber trotzdem mal selber noch versuchen; vom Prinzip her sollte es ja nicht all zu schwer sein. Werde mich melden, wenn ich's geschafft hab. LG: Input |
|
| Nach oben |
|
|
grindstone
Anmeldungsdatum: 03.10.2010
Beiträge: 1211
Wohnort: Ruhrpott
|
| Verfasst am: 19.08.2014, 13:16 Titel: |
|
|
@ Sebastian:
Ich habe unsere beiden Programme mal miteinander verglichen: Beim Suchen von einzelnen Wörtern ist dein Programm ca. 15 mal so schnell wie meins, da helfen auch alle Programmiertricks nichts.  Dafür habe ich beim Einlesen der Datei die Nase vorn. Ich habe mir daher erlaubt, beides zu kombinieren und deine Einleseroutine umzuschreiben. Das Resultat habe ich nach http://www.freebasic-portal.de/porticula/wortzaehler-1773.html hochgeladen. Die Vermischung unserer Programmierstile sieht nicht wirklich schön aus, aber es funktioniert: Das Einlesen geht jetzt gut 10mal so schnell. Dafür habe ich beim Einlesen der Datei die Nase vorn. Ich habe mir daher erlaubt, beides zu kombinieren und deine Einleseroutine umzuschreiben. Das Resultat habe ich nach http://www.freebasic-portal.de/porticula/wortzaehler-1773.html hochgeladen. Die Vermischung unserer Programmierstile sieht nicht wirklich schön aus, aber es funktioniert: Das Einlesen geht jetzt gut 10mal so schnell.
Eine Macke hat das Programm allerdings (noch): Wenn man nach einem Wort sucht, das im Text nicht vorkommt, stürzt es ab.
Gruß
grindstone
_________________
For ein halbes Jahr wuste ich nich mahl wie man Proggramira schreibt. Jetzt bin ich einen! |
|
| Nach oben |
|
|
Sebastian
Administrator
Anmeldungsdatum: 10.09.2004
Beiträge: 5969
Wohnort: Deutschland
|
| Verfasst am: 19.08.2014, 19:27 Titel: |
|
|
| grindstone hat Folgendes geschrieben: | | ca. 15 mal so schnell |
Ja, es ist halt ein ganz anderer Ansatz. Bei einem Array, in dem sequentiell nachgeschlagen wird, nimmt der durchschnittliche Nachschlageaufwand mit der Größe des Arrays (also mit der Anzahl unterschiedlicher Wörter) zu. Je mehr Wörter im Array sind, desto länger dauert es durchschnittlich, bis das gesuchte gefunden wird. Wenn das gesuchte Wort gar nicht in der Liste ist, muss sogar das ganze Array durchsucht werden, wenn man es nicht nach dem Einlesen sortiert.
Bei der Baum-Methode ist der Nachschlage-Aufwand nur von der Länge des nachzuschlagenden Wortes abhängig. Das Nachschlagen eines bspw. 8-buchstabigen Worts verursacht immer den gleichen Aufwand - egal, ob 3 Wörter oder 3 Millionen Wörter verwaltet werden.
Der Performance-Unterschied zwischen Array und Baum wird also mit zunehmender Wortanzahl / Datenmenge noch erheblicher.
| grindstone hat Folgendes geschrieben: | | Das Einlesen geht jetzt gut 10mal so schnell. |
Der Geschwindigkeitsunterschied beim Einlesen begründet sich damit, dass dein Code die komplette Datei zuerst in einem Stück in den RAM einliest und dann aus dem String im RAM die Wörter extrahiert. Operationen auf Daten im RAM sind viel schneller als auf Festplattendaten. Allerdings ist der Nachteil der Methode, dass die ganze Datei zuerst in einem Stück eingelesen werden muss (ggf. auch eine 1 GB große Datei). Mein Code liest Zeichen für Zeichen ein und der Wortpuffer wird nur so lang wie das längste Wort. Man spart also womöglich gigabyteweise Speicher.
Ist mal wieder ein "Trade-Off", wo man abwägen muss, in welche Richtung man optimieren möchte.
| grindstone hat Folgendes geschrieben: | | Eine Macke hat das Programm allerdings (noch): Wenn man nach einem Wort sucht, das im Text nicht vorkommt, stürzt es ab. |
Ups, Bug ist behoben. (Link ist gleich geblieben.)
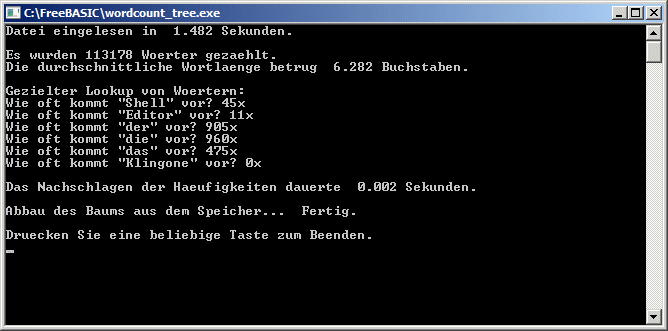
_________________
Die gefährlichsten Familienclans | Opas Leistung muss sich wieder lohnen - für 6 bis 10 Generationen! |
|
| Nach oben |
|
|
Muttonhead

Anmeldungsdatum: 26.08.2008
Beiträge: 562
Wohnort: Jüterbog
|
| Verfasst am: 19.08.2014, 20:13 Titel: |
|
|
Find das mit dem Baum recht spannen aber mir geht hier ein wenig die Vorstellung verloren.
Angenommen hab "nur" meine 26 Buchstaben:
eine Hand mit 26 Fingern und auf jedem Finger wieder eine (mit 26 Finger) usw?
Mutton |
|
| Nach oben |
|
|
Sebastian
Administrator
Anmeldungsdatum: 10.09.2004
Beiträge: 5969
Wohnort: Deutschland
|
| Verfasst am: 19.08.2014, 20:24 Titel: |
|
|
| Muttonhead hat Folgendes geschrieben: | Angenommen hab "nur" meine 26 Buchstaben:
eine Hand mit 26 Fingern und auf jedem Finger wieder eine (mit 26 Finger) usw? |
Genau.
Nicht an jedem Finger geht es weiter zu einer tieferliegenden Hand, sondern auf einem Finger kann auch NULL stehen. Und auf jeder Handfläche steht drauf, wie häufig das Wort vorkommt, das bei dieser Hand endet.
Beim Wort "HAND" würde der Pfad H->A->N->D verfolgt (4 Ebenen tief) und dann der Zähler vom D am Ende um 1 erhöht.
_________________
Die gefährlichsten Familienclans | Opas Leistung muss sich wieder lohnen - für 6 bis 10 Generationen! |
|
| Nach oben |
|
|
Toa-Nuva
Anmeldungsdatum: 14.04.2006
Beiträge: 204
Wohnort: München
|
| Verfasst am: 20.08.2014, 02:33 Titel: |
|
|
Diese Datenstruktur nennt sich übrigens Trie.
Was den Tradeoff zwischen Einlesen einzelner Zeichen vs kompletter Dateien angeht, da würde ich eigentlich immer einen Puffer fester Größe (z.B. 16 oder 32 KB) verwenden. Dann hängt es nicht von der Dateigröße ab, wie viel Arbeitsspeicher man verbraucht, und trotzdem sollte das Lesen nicht (wahrnehmbar) länger dauern, als würde man die komplette Datei auf einmal einlesen.
Wenn die Programmiersprache bzw deren Bibliotheken von sich aus nicht schon so was anbieten, würde es sich empfehlen, selbst einen Wrapper für die zur Verfügung stehenden Dateizugriffsoperationen zu schreiben.
Zeichenweises Einlesen direkt von der Festplatte würde ich auf jeden Fall auf den Tod vermeiden.
_________________
704 Signature not found |
|
| Nach oben |
|
|
grindstone
Anmeldungsdatum: 03.10.2010
Beiträge: 1211
Wohnort: Ruhrpott
|
| Verfasst am: 20.08.2014, 03:13 Titel: |
|
|
| Sebastian hat Folgendes geschrieben: | | Operationen auf Daten im RAM sind viel schneller als auf Festplattendaten |
Natürlich ist das schneller, deshalb mache ich es ja. Das alleine bringt allerdings "nur" eine verfünffachung der Geschwindigkeit. Das Isolieren der einzelnen Wörter mithilfe von 2 Pointern, die sich am String "entlanghangeln", verdoppelt dann noch einmal das Tempo.
| Sebastian hat Folgendes geschrieben: | | Man spart also womöglich gigabyteweise Speicher |
Mit dem Problem der begrenzten Stringlänge habe ich mich zu QBasic-Zeiten herumgeschlagen (max. 64kB für alle Daten), es ist -bei Bedarf- ganz einfach zu lösen: Es wird immer nur eine speicherverträgliche Menge an Daten geladen. Sobald ein Pointer das Ende des Strings erreicht, wird der vordere Teil des Strings, der schon abgearbeitet ist, gelöscht und eine geeignete Menge nachgeladen und hinten drangehängt. Das ist immer noch deutlich schneller, als jedes Zeichen einzeln aus der Datei zu holen.
Und überhaupt der Speicherbedarf: Der komplette Baum belegt ca. 77,6 MB. also etwa das 78fache der Ausgangsdatei, da fällt der eine String in Dateigröße eigentlich kaum noch ins Gewicht. Oder anders ausgedrückt: Wenn für einen String in Dateilänge nicht genug Speicher da ist, reicht es für den Baum erst recht nicht.
Nur zum Vergleich: Die fertig eingelesene und alphabetisch geordnete Tabelle mit den dazugehörigen Häufigkeiten ist gerade einmal 209 kB groß.
Gruß
grindstone
_________________
For ein halbes Jahr wuste ich nich mahl wie man Proggramira schreibt. Jetzt bin ich einen! |
|
| Nach oben |
|
|
Toa-Nuva
Anmeldungsdatum: 14.04.2006
Beiträge: 204
Wohnort: München
|
| Verfasst am: 20.08.2014, 14:23 Titel: |
|
|
| grindstone hat Folgendes geschrieben: | | Und überhaupt der Speicherbedarf: Der komplette Baum belegt ca. 77,6 MB. also etwa das 78fache der Ausgangsdatei, da fällt der eine String in Dateigröße eigentlich kaum noch ins Gewicht. Oder anders ausgedrückt: Wenn für einen String in Dateilänge nicht genug Speicher da ist, reicht es für den Baum erst recht nicht. |
Je größer die Datei ist, desto eher kommen darin aber auch Wörter (bzw Präfixe) mehrfach vor. Und die erzeugen dann ja keine zusätzlichen Speicherkosten (Knoten im Baum). D.h. die Größe des Baumes sollte deutlich sublinear mit der Größe der Datei wachsen. Wenn die Datei nur ein einziges Wort enthält, sollte der Baum grob überschlagen sogar ~900 Mal so viel Speicher belegen wie die Datei. Kann ja mal jemand ausprobieren, wie groß eine Datei (mit sinnvollem Inhalt) sein muss, bis der Speicherbedarf des Baumes von der Dateigröße überholt wird.
Und natürlich gäbe es noch viele Möglichkeiten, Speicher zu sparen. Wenn man z.B. jedes Wort in eine Kombination von ASCII-Kleinbuchstaben normalisiert, sind nur noch 26 (statt 224) Pointer in jedem Knoten nötig. Oder man könnte eine dynamisch wachsende Hash-Tabelle o.ä. anstelle eines Arrays fester Größe verwenden verwenden, sodass ein Knoten mit wenigen Kind-Knoten (Pointern, die nicht null sind) auch weniger Speicher belegt als einer mit vielen Kind-Knoten.
_________________
704 Signature not found |
|
| Nach oben |
|
|
Sebastian
Administrator
Anmeldungsdatum: 10.09.2004
Beiträge: 5969
Wohnort: Deutschland
|
| Verfasst am: 20.08.2014, 15:47 Titel: |
|
|
| Toa-Nuva hat Folgendes geschrieben: | | Je größer die Datei ist, desto eher kommen darin aber auch Wörter (bzw Präfixe) mehrfach vor. Und die erzeugen dann ja keine zusätzlichen Speicherkosten (Knoten im Baum). D.h. die Größe des Baumes sollte deutlich sublinear mit der Größe der Datei wachsen. |
ja, hätte es nicht besser formulieren können
Für jede Wiederholung eines Wortes wird ja lediglich der UInteger-Zähler im Knoten inkrementiert. Die Größe des Baumes bzw. der Speicherbedarf ist, wie Toa-Nuva schon schreibt, nur von der Anzahl verschiedener Wörter abhängig. Je mehr Text man eingelesen hat, desto seltener wird der Fall, dass man auf ein Wort stößt, das bisher keinen Pfad hat.
Wenn du eine 10 GB große Datei verarbeiten lässt, die nur aus "Hallo Welt"-Wiederholungen besteht, hast du nur "eine Hand voll" Knoten mit wenigen kB Speicherbedarf.
Bei Texten mit natürlicher Sprache lässt sich der RAM-Bedarf des Baums als Sättigungskurve beschreiben mit ganz geringen RAM-Grenzkosten pro zusätzlicher Textmenge, wenn erst mal ein Vorrat an Text eingelesen ist.
Hab mal versucht, das grob zu skizzieren:
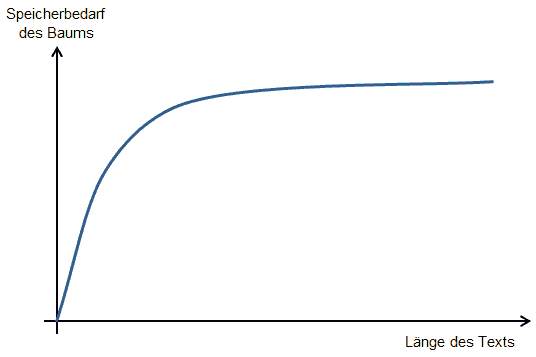
Hat jemand Lust, mit FB+Screen eine grafische Darstellung des Baumwachstums zu basteln, wenn z. B. der Volltext der Bibel oder der deutschen Wikipedia eingelesen wird?
Viele Grüße!
Sebastian
_________________
Die gefährlichsten Familienclans | Opas Leistung muss sich wieder lohnen - für 6 bis 10 Generationen! |
|
| Nach oben |
|
|
grindstone
Anmeldungsdatum: 03.10.2010
Beiträge: 1211
Wohnort: Ruhrpott
|
| Verfasst am: 21.08.2014, 02:17 Titel: |
|
|
| Sebastian hat Folgendes geschrieben: | | Hat jemand Lust, mit FB+Screen eine grafische Darstellung des Baumwachstums zu basteln, wenn z. B. der Volltext der Bibel oder der deutschen Wikipedia eingelesen wird? happy |
Bring mich nicht auf dumme Gedanken! Ich habe mit dem Thema sowieso schon viel mehr Zeit verbracht, als ich eigentlich wollte...
.....
 ==> ==>  ==> ==>  ==> ==>  ==> ==> ==> ==>  ==> ==>
... OK, die Bibel ist kein Problem, aber wie komme ich an den Volltext von Wikipedia? Und -Frage an den Administrator- wie kann ich hier im Forum einen Screenshot posten?
Gruß
grindstone
_________________
For ein halbes Jahr wuste ich nich mahl wie man Proggramira schreibt. Jetzt bin ich einen! |
|
| Nach oben |
|
|
nemored

Anmeldungsdatum: 22.02.2007
Beiträge: 4597
Wohnort: ~/
|
| Verfasst am: 21.08.2014, 08:34 Titel: |
|
|
Der Volltext der Wikipedia wird wohl schwierig - außer du schreibst dir einen Crawler - einzelne Artikel könntest du aber als Ebook sichern, wobei auch die Ausgabe als PDF oder ODF unterstützt wird.
_________________
Deine Chance beträgt 1:1000. Also musst du folgendes tun: Vergiss die 1000 und konzentriere dich auf die 1. |
|
| Nach oben |
|
|
RockTheSchock
Anmeldungsdatum: 04.04.2007
Beiträge: 138
|
|
| Nach oben |
|
|
grindstone
Anmeldungsdatum: 03.10.2010
Beiträge: 1211
Wohnort: Ruhrpott
|
| Verfasst am: 21.08.2014, 10:20 Titel: |
|
|
Unter ftp://ftp5.gwdg.de/pub/wikipedia/DVD/Wikipedia.zeno kann man den kompletten Text herunterladen (Dateigröße ca. 3 GB), allerdings nicht als lesbaren Text, sondern (angeblich) im XML-Format. Es gibt dazu Anzeigetools, aber ob man das Ganze damit in ASCII-Text konvertieren kann, weiß ich nicht, und Open Office dürfte vor dieser Dateigröße wohl kapitulieren. Ich werde mal downloaden, aber das dauert...
Die Bibel als reiner Text ist übrigens gerade mal 4 MB groß. 
Gruß
grindstone
EDIT: Hier ein Screenshot einer ersten "quick & dirty" - Version der grafischen Darstellung des Speicherbedarfs (mit der Bibel als Quelltext, AT + NT)
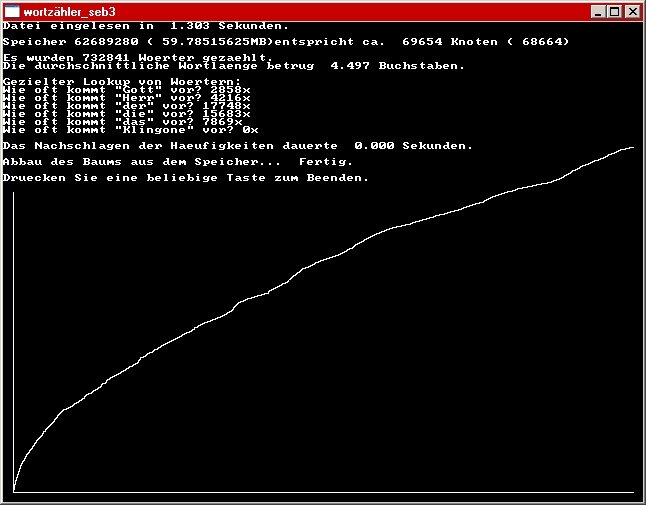
_________________
For ein halbes Jahr wuste ich nich mahl wie man Proggramira schreibt. Jetzt bin ich einen!
Zuletzt bearbeitet von grindstone am 14.10.2014, 07:03, insgesamt einmal bearbeitet |
|
| Nach oben |
|
|
Muttonhead
Anmeldungsdatum: 26.08.2008
Beiträge: 562
Wohnort: Jüterbog
|
| Verfasst am: 21.08.2014, 15:17 Titel: |
|
|
Ist das der komplette Graph? Würde ja bedeuten das die Bibel bis zum Schluß fleißig mit neuen Wörtern bestückt ist, der Graph ist ja nun alles andere als grade
Mutton |
|
| Nach oben |
|
|
|
|
Du kannst keine Beiträge in dieses Forum schreiben.
Du kannst auf Beiträge in diesem Forum nicht antworten.
Du kannst deine Beiträge in diesem Forum nicht bearbeiten.
Du kannst deine Beiträge in diesem Forum nicht löschen.
Du kannst an Umfragen in diesem Forum nicht mitmachen.
|
|

