 |
Das deutsche QBasic- und FreeBASIC-Forum
Für euch erreichbar unter qb-forum.de, fb-forum.de und freebasic-forum.de!
|
| Vorheriges Thema anzeigen :: Nächstes Thema anzeigen |
| Autor |
Nachricht |
nemored

Anmeldungsdatum: 22.02.2007
Beiträge: 4597
Wohnort: ~/
|
 Verfasst am: 21.08.2014, 18:15 Titel: Verfasst am: 21.08.2014, 18:15 Titel: |
 |
|
Die Bibel hat immerhin einen Entstehungszeitraum von etwa 1000 Jahren, da wundert es mich nicht so sehr, dass sich der Sprachgebrauch mit der Zeit ändert. Die Bücher des NT ist zudem im Original in einer anderen Sprache geschrieben als die Bücher des AT, was sprachlich sicher auch in der Übersetzung Folgen hat - mal davon abgesehen, dass sie an einen anderen Kulturkreis adressiert sind (hellenistischer Raum). Möglicherweise ist die Bibel da gar kein so gutes Demonstrationsobjekt. 
Besser wäre wahrscheinlich, das Gesamtwerk eines einzelnen Schriftstellers zu betrachten, wobei es auch da große Qualitätsunterschiede gibt - einige große Autoren zeichnen sich durch einen ungeheure Sprachreichtum aus, anderen Autoren reichen vermutlich schon so um die 2000 Wörter. 
Letztlich nicht überraschend, aber dennoch beeindruckend finde ich die Suchgeschwindigkeit.
_________________
Deine Chance beträgt 1:1000. Also musst du folgendes tun: Vergiss die 1000 und konzentriere dich auf die 1. |
|
| Nach oben |
|
 |
Sebastian
Administrator

Anmeldungsdatum: 10.09.2004
Beiträge: 5969
Wohnort: Deutschland
|
| Verfasst am: 21.08.2014, 19:42 Titel: |
|
|
Mit nur 4 MB Dateigröße, den vielen Eigennamen und der sprachlichen Entwicklung über den Entstehungszeitraum hinweg kommt man bei der untersuchten Bibelübersetzung wohl noch nicht in den erwarteten allmählichen Sättigungsbereich.  Vielleicht müsste man etwas größeres ausprobieren (z. B. 400 MB oder 4 GB). Und nemored stimme ich auch zu. Das könnte ein sinnvolles Test-Setting sein. Vielleicht müsste man etwas größeres ausprobieren (z. B. 400 MB oder 4 GB). Und nemored stimme ich auch zu. Das könnte ein sinnvolles Test-Setting sein.
_________________

Die gefährlichsten Familienclans | Opas Leistung muss sich wieder lohnen - für 6 bis 10 Generationen! |
|
| Nach oben |
|
|
grindstone
Anmeldungsdatum: 03.10.2010
Beiträge: 1211
Wohnort: Ruhrpott
|
| Verfasst am: 22.08.2014, 02:23 Titel: |
|
|
Hallo!
Ja, das ist der komplette Graph. Ich habe mich auch gewundert und einen Fehler bei der Auswertung vermutet, aber da scheint alles korrekt zu sein. Der x-Wert ist der aktuelle Dateipointer in bezug auf die Dateilänge, und der y-Wert ist die aktuelle Anzahl der Knoten, beides umgerechnet auf die Bildschirmkoordinaten.
Die Darstellung täuscht übrigens etwas. Gerade am Anfang ist der Graph sehr steil, um aber schon nach kurzer Zeit in einen fast linearen Teil überzugehen. Das ist eigentlich logisch: Die am häufigsten vorkommenden Wörter (der, die, das, und, in, ...) sind alle recht kurz und sehr häufig und somit schon nach kurzer Zeit komplett. Und ein einmal vorgekommenes Wort belegt im Baum ja keinen weiteren Speicherplatz mehr. Wenn man in einem zweiten Graphen die Anzahl der unterschiedlichen Wörter darstellt, sieht man, daß der Kurvenverlauf fast identisch ist.
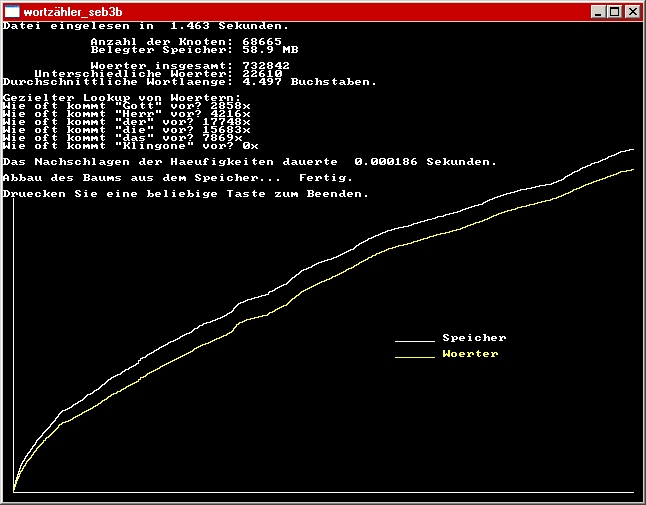
Würde man jetzt noch die Wörter nach ihrer Häufigkeit auflisten...
Hey, sind wir hier gerade dabei, ein Analysetool für Germanisten zu entwickeln? 
Hier der Sourcecode (noch in der Entwicklung befindlich).
Und die Bibel zum Download gibt es hier
| nemored hat Folgendes geschrieben: | | anderen Autoren reichen vermutlich schon so um die 2000 Wörter. |
Böse Zungen behaupten ja, es gäbe in Deutschland eine bekannte Tageszeitung, die mit 500 Wörtern auskommt... 
| nemored hat Folgendes geschrieben: | | beeindruckend finde ich die Suchgeschwindigkeit |
Und dabei wird das meiste von der Zeit für das Drucken benötigt. Die eigentliche Suchgeschwindigkeit ist noch viel beeindruckender. Die Zeit für eine einzelne Suche liegt in der Gegend von 100 ns.
Gruß
grindstone
_________________
For ein halbes Jahr wuste ich nich mahl wie man Proggramira schreibt. Jetzt bin ich einen! |
|
| Nach oben |
|
|
Muttonhead

Anmeldungsdatum: 26.08.2008
Beiträge: 562
Wohnort: Jüterbog
|
| Verfasst am: 22.08.2014, 11:42 Titel: |
|
|
Vielleicht ists ja nur ein Skalierungsproblem:
wenn man 68000 Knoten zu 4 MB Zeichen im Verhältnis sieht dürfte der Graph bei 640 px Breite eigentlich nur knappe 11 px hoch sein? Wenn ich mich jetzt nicht allzu arg verrechnet hab.
Danach siehts dann eher nach dem erwarteten Ergebnis aus
Mich würde ja eher eine Visualisierung des Baumes interessieren. Und ob man daran vielleicht nen deutschen von nem englischen Text unterscheiden könnte, oder den Verfasser, halt wie nen Fingerprint...
Mutton |
|
| Nach oben |
|
|
grindstone
Anmeldungsdatum: 03.10.2010
Beiträge: 1211
Wohnort: Ruhrpott
|
| Verfasst am: 22.08.2014, 13:07 Titel: |
|
|
Dazu fällt mir ganz spontan ein Sketch von Loriot ein, bei dem ein Pferderennen im Superbreitbildformat im Fernsehen übertragen wurde. Das Bild war 50 cm breit und 2 cm hoch. Man hatte also die komplette Rennbahn im Blick... 
Die Skalierungen für Höhe und Breite lassen sich völlig unabhängig voneinander wählen, und da der Graph nur eine qualitative Aussage über den Verlauf der Speicherbelegung machen soll, wählt man sie am besten so, daß der gesamte zur Verfügung stehende Platz ausgenutzt wird.
Könntest du näher erläutern, was du am Baum visualisiert haben möchtest? Ich kann mir da nichts drunter vorstellen.
Gruß
grindstone
_________________
For ein halbes Jahr wuste ich nich mahl wie man Proggramira schreibt. Jetzt bin ich einen! |
|
| Nach oben |
|
|
Muttonhead
Anmeldungsdatum: 26.08.2008
Beiträge: 562
Wohnort: Jüterbog
|
| Verfasst am: 22.08.2014, 13:34 Titel: |
|
|
Naja, den Traffic der Knoten verschiedenfarbig darstellen. Ähnlich einer "Temperaturkarte" beim Wetterbericht.
Könnte mir vorstellen das es Knoten gibt, wo "viele" Worte durchlaufen.
Vielleicht ist sowas ja für irgend was charakteristisch.
Vielleicht aber auch nicht und es ist eine gleichmäßige Verteilung
Ob das machbar ist bezweifle ich, da sich die Breite des Baumes in jeder tieferen Ebene extrem potenziert.
Im Prinzip ein ein Baum, bei dem beispielsweise ein starker Ast bis hin zu irgend nem kleinen Zweig stark "glühen" weil viele Worte dort enden. Andere Bereiche des Baumes wären dunkel= wenig Worte.
edit: um bei dem Bild zu bleiben: der Stamm glüht natürlich richtg dolle... irgendwo muß ja jedes wort beginnen
Ansich stecken diese Informationen ja schon in der Struktur drin...
Mutton |
|
| Nach oben |
|
|
grindstone
Anmeldungsdatum: 03.10.2010
Beiträge: 1211
Wohnort: Ruhrpott
|
| Verfasst am: 22.08.2014, 23:56 Titel: |
|
|
Interessanter Gedanke. Das hat ein bisschen was von einer DNA-Probe. Da werden ja auch -zumindest dem Prinzip nach- die DNA-Stränge zerschnitten und der Größe nach geordnet. Die Hauptschwierigkeit bei der Darstellung (beim Text meine ich jetzt) dürfte der immense Unterschied zwischen Tiefe und Breite des Baumes sein. Ich werde mir das mal durch den Kopf gehen lassen.
Die Sprache eines Textes dürfte sich übrigens anhand der 3 - 5 am häufigsten vorkommenden Wörter eindeutig identifizieren lassen.
Gruß
grindstone
_________________
For ein halbes Jahr wuste ich nich mahl wie man Proggramira schreibt. Jetzt bin ich einen! |
|
| Nach oben |
|
|
Input
Anmeldungsdatum: 28.07.2014
Beiträge: 59
|
| Verfasst am: 23.08.2014, 14:01 Titel: |
|
|
| Hallo liebes Forum. Wollte mich nochmals für eure Hilfe bedanken. Grindstone: Dein Programm läuft perfekt; ich werd da nix mehr basteln, würd ich nicht besser hinkriegen!! Mit dem Andern konnte ich leider nicht viel anfangen, da ich die Sprache nicht so gut versteh und im Programmieren (noch?) kein Hirsch bin. LG: Input |
|
| Nach oben |
|
|
grindstone
Anmeldungsdatum: 03.10.2010
Beiträge: 1211
Wohnort: Ruhrpott
|
| Verfasst am: 24.08.2014, 01:49 Titel: |
|
|
@Input:
Mein Lösungsansatz ist sicher leichter nachzuvollziehen, dafür ist Sebastians Algorithmus irre schnell. Und tröste dich: ich habe auch 2 Tage gebraucht, um ihn zu verstehen.
Und um das Ganze noch etwas komplizierter zu machen, habe ich in die Sub "traverseTree" die Möglichkeit eingebaut, optional eine Callback-Routine aufzurufen, die die Auswertung des Baumes übernehmen kann (mit ein paar Beispielen).
Viel Spaß beim Herumspielen damit!
http://users.freebasic-portal.de/grindstone/Codes/wortz%c3%a4hler_seb3d.bas
Übrigens: Der etwas unerwartete Kurvenverlauf bei der Debiananleitung könnte daher rühren, daß der Inhalt zu großen Teilen aus englischem Text besteht.
Gruß
grindstone
_________________
For ein halbes Jahr wuste ich nich mahl wie man Proggramira schreibt. Jetzt bin ich einen! |
|
| Nach oben |
|
|
grindstone
Anmeldungsdatum: 03.10.2010
Beiträge: 1211
Wohnort: Ruhrpott
|
| Verfasst am: 24.08.2014, 09:17 Titel: |
|
|
Frage an die Experten:
Die Sub " traverseTree" sieht bei mir inzwischen so aus:
| Code: | Sub traverseTree (node As tNode Ptr, index As UByte, path As String, pluginPointer As Any Ptr = 0,flag As ZString*1 = "")
Dim wordPlugin As Sub (text As String, count As UInteger)
Dim nodePlugin As Sub (node As tNode Ptr)
If (node = NULL) Then Return
If pluginPointer <> 0 And flag = "n" Then
nodePlugin = pluginPointer
nodePlugin(node)
EndIf
If (node->count > 0) Then
If pluginPointer <> 0 And flag = "w" Then
wordPlugin = pluginPointer
wordPlugin(path,node->count)
ElseIf flag = "" Then
Print path & " => " & node->count & " x"
Sleep 50
EndIf
End If
For i As Integer = 1 To treeSubNodeCount
If (node->subNodes(i) <> NULL) Then
traverseTree (node->subNodes(i), i, path + Chr(i+skipChars),pluginPointer,flag)
End If
Next i
End Sub |
Ich würde mir das Flag gerne sparen, indem ich die Sub "Plugin" überlade, etwa so: | Code: | Dim Plugin OverLoad As Sub (text As String, count As UInteger)
Dim Plugin As Sub (node As tNode Ptr) |
Aber wenn ich das versuche, bekomme ich eine Fehlermeldung. Wie kann man eine Callback-Routine überladen, oder geht das nicht?
EDIT: Hier eine neue Version mit einer (sehr experimentellen) Visualisierung des Baumes.
EDIT 2: Ziehe die Frage zurück, war ein Denkfehler meinerseits. Da der Funktionspointer ohne Parameter übergeben wird, könnte der Compiler auf keinen Fall feststellen, welche Sub er aufrufen muß, das Flag ist also notwendig.
Gruß
grindstone
_________________
For ein halbes Jahr wuste ich nich mahl wie man Proggramira schreibt. Jetzt bin ich einen! |
|
| Nach oben |
|
|
grindstone
Anmeldungsdatum: 03.10.2010
Beiträge: 1211
Wohnort: Ruhrpott
|
| Verfasst am: 28.08.2014, 08:20 Titel: |
|
|
Hier nun die vorläufig endgültige Version des Programms, mit dem Potential, mich bei den Betreibern von Wikipedia äußerst unbeliebt zu machen.
Mithilfe des Codebeispiels "Websites selbst verarbeiten" von PMedia habe ich es internetfähig gemacht, und es nutzt die Funktion "Zufälliger Artikel" von Wikipedia, um eben jene zufälligen Artikel in einer Schleife reihenweise herunterzuladen und auszuwerten.
Kurz zur Bedienung: Mit den Zifferntasten 1 - 8 wird die Darstellung gewählt, mit + und - lässt sich zwischen 640 x 480 und 1200 x 800 umschalten, und Esc beendet das Programm.
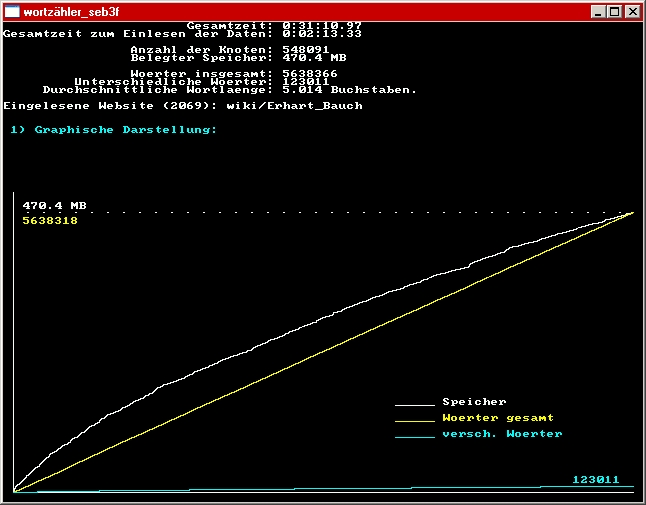
Wie man sieht, ist der Sättigungseffekt nicht annähernd so stark wie vermutet. Vielleicht ist ein Lexikon im Hinblick auf die Anzahl der verwendeten Wörter einfach zu vielseitig.
Gruß
grindstone
EDIT: @Sebastian: Ich sehe gerade, daß die Funktion "lookupWordCount" offenbar nicht richtig arbeitet. Obwohl ich im Eingangsfilter die Wortlänge gerade auf 2 Zeichen begrenzt habe, bekomme ich für "Computernerd" 23 Treffer angezeigt.
EDIT 2: Fehler gefunden. "Len(word)" liefert einen falschen Wert (warum auch immer). Abhilfe: "word" in eine andere Stringvariable kopieren und mit dieser Variable weiterarbeiten.
_________________
For ein halbes Jahr wuste ich nich mahl wie man Proggramira schreibt. Jetzt bin ich einen! |
|
| Nach oben |
|
|
Toa-Nuva
Anmeldungsdatum: 14.04.2006
Beiträge: 204
Wohnort: München
|
| Verfasst am: 28.08.2014, 15:22 Titel: |
|
|
| grindstone hat Folgendes geschrieben: | | Wie man sieht, ist der Sättigungseffekt nicht annähernd so stark wie vermutet. Vielleicht ist ein Lexikon im Hinblick auf die Anzahl der verwendeten Wörter einfach zu vielseitig. |
Einerseits das. Immerhin kommen auf Wikipedia auch immer wieder Namen, und Begriffe aus anderen Sprachen vor.
Mir fallen auch noch mehr Gründe ein, wobei es natürlich immer vom Anwendungsfall abhängt, ob das gewollt ist oder nicht:
- Stemming. "rennen" und "renne" sind zwei verschiedene Wörter. Eventuell möchte man da erstmal einen Stemmer drüberlaufen lassen, damit beide Begriffe als dasselbe Wort erkannt werden.
- Zusammengesetzte Wörter. Davon kann man gerade im Deutschen ja beliebig viele bilden. Je nach Anwendungsfall will man aber vielleicht nicht das komplette zusammengesetzte Wort zählen, sondern die einzelnen Teilwörter. Das wäre natürlich etwas schwer zu implementieren, aber man könnte ja exemplarisch z.B. einfach englische statt deutsche Texte verwenden.
- Groß- und Kleinschreibung. Kommt ein Wort zum ersten Mal am Satzbeginn vor, wird es als neues Wort gezählt, selbst wenn es zuvor schon tausendfach im Text vorgekommen ist - einfach weil es jetzt plötzlich mit Großbuchstaben am Anfang geschrieben wird. Man sollte also darüber nachdenken, ob man nicht einfach alle Zeichen in Kleinbuchstaben umwandeln will.
- Satzzeichen. Wie ich schon mal gesagt habe, ist das Programm etwas zu großzügig damit, was als ein Wort betrachtet wird. Wenn z.B. irgendwas in Klammern dasteht, dann wird das letzte Wort mitsamt der schließenden Klammer als ein Wort gewertet. (Das erste Wort wäre in dem Fall nicht betroffen, da in deinem Code das erste Zeichen immer ein Buchstabe sein muss.) Wie ich schon mal gesagt habe, ich würde alles außer Buchstaben als Worttrenner behandeln.
- Rechtschreibfehler. Ist natürlich fraglich, wie viel man dagegen unternehmen kann/will.
- Zeichensätze. Die Seiten auf Wikipedia sind in UTF-8, was von dem Programm vermutlich nicht berücksichtigt wird. Einerseits bedeutet das, dass viele "Sonderzeichen" für zwei oder mehr Zeichen gehalten werden (mehr Knoten als nötig); Andererseits heißt das auch, dass es noch viel mehr (Satz-)Zeichen gibt, die berücksichtigt werden müssen. Deutsche Anführungszeichen dürften z.B. dazu führen, dass das erste und das letzte Wort im Zitat für neue Wörter gehalten werden, selbst wenn die Wörter bereits (ohne Anführungszeichen) bekannt wären.
Gibt sicher noch mehr, aber das ist mir gerade so auf die Schnelle eingefallen.
_________________
704 Signature not found |
|
| Nach oben |
|
|
Jojo
alter Rang

Anmeldungsdatum: 12.02.2005
Beiträge: 9736
Wohnort: Neben der Festplatte
|
| Verfasst am: 28.08.2014, 16:17 Titel: |
|
|
Sicher sollte auch bedacht werden, dass die Wikipedia noch mehr Autoren und damit Schreibstile hat als die Bibel...
_________________
» Die Mathematik wurde geschaffen, um Probleme zu lösen, die es nicht gäbe, wenn die Mathematik nicht erschaffen worden wäre.
 |
|
| Nach oben |
|
|
grindstone
Anmeldungsdatum: 03.10.2010
Beiträge: 1211
Wohnort: Ruhrpott
|
| Verfasst am: 29.08.2014, 01:39 Titel: |
|
|
| Jojo hat Folgendes geschrieben: | | ...dass die Wikipedia noch mehr Autoren und damit Schreibstile hat als die Bibel... |
Sag ich doch: vielseitig.
@Toa-Nuva:
Sicher kann man den Eingangstext noch (viel) besser ausfiltern, indem man beispielsweise alle Links und http - Befehle sorgfältig eliminiert. Aber ich denke, auch das würde nur zu marginalen Änderungen im Kurvenverlauf führen. Um eine Kurve zu bekommen, wie Sebastian sie angedeutet hat, musst du die Wortlänge auf 2 Zeichen begrenzen. Ich möchte das Forum nicht mit Screenshots zumüllen, probier es einfach selber aus (Zeile 142). Welche Aussagekraft so eine Kurve dann noch hat, sei mal dahingestellt. Was wieder einmal zeigt: Mit Statistik kann man alles beweisen.
Gruß
grindstone
_________________
For ein halbes Jahr wuste ich nich mahl wie man Proggramira schreibt. Jetzt bin ich einen! |
|
| Nach oben |
|
|
grindstone
Anmeldungsdatum: 03.10.2010
Beiträge: 1211
Wohnort: Ruhrpott
|
| Verfasst am: 01.09.2014, 10:54 Titel: |
|
|
So, hier nun die vorläufig unwiderruflich letzte Version des Zählprogramms.
Ich habe es um eine Function erweitert, die aus html den "normalen" Text herausfiltert, und um einen rudimentären UTF-8 - nach - ASCII - Konverter. Außerdem habe ich die Einbindung der Auswerte-Plugins etwas vereinfacht, und der cyanfarbige Graph stellt jetzt das Verhältnis [korrektur]der unterschiedlichen Wörter zu den Gesamtwörtern[/korrektur] dar.
Da ich denke, daß es mittlerweite ein gutes Grundgerüst für ein Analysetool darstellt, habe ich es unter den Programmbeispielen verewigt.
Zum Testen habe ich neben der deutschen auch einmal die englische Wikipedia-Site heimgesucht. Hier zum Vergleich jeweils ein Screenshot von der deutschen und der englischen Ausgabe nach etwas über einer Stunde Laufzeit. Für den Fall, daß jemand das noch für andere Sprachen ausprobieren möchte, habe ich den Hilfscode zum Ermitteln der entsprechenden Kennungen mal auskommentiert im Sourcecode dringelassen.
Gruß
grindstone
_________________
For ein halbes Jahr wuste ich nich mahl wie man Proggramira schreibt. Jetzt bin ich einen!
Zuletzt bearbeitet von grindstone am 02.09.2014, 03:13, insgesamt einmal bearbeitet |
|
| Nach oben |
|
|
nemored
Anmeldungsdatum: 22.02.2007
Beiträge: 4597
Wohnort: ~/
|
| Verfasst am: 01.09.2014, 11:44 Titel: |
|
|
Mich irritiert, dass die Kurve "gesamt : versch." fällt. Heißt das, dass der Anteil neuer Wörter verhältnismäßig schneller wächst als die Anzahl aller Wörter insgesamt? Das wäre ja genau das Gegenteil von der Ausgangsvermutung.
Nett finde ich den im Screenshot eingefangenen Artikel, der bestimmt sehr repräsentativ für deutschsprachige Texte ist.
_________________
Deine Chance beträgt 1:1000. Also musst du folgendes tun: Vergiss die 1000 und konzentriere dich auf die 1. |
|
| Nach oben |
|
|
grindstone
Anmeldungsdatum: 03.10.2010
Beiträge: 1211
Wohnort: Ruhrpott
|
| Verfasst am: 02.09.2014, 03:20 Titel: |
|
|
Stimmt, die Beschriftung ist irreführend. Statt 9,87 müsste dort korrekterweise 1:9,87 stehen (oder 0,1013, aber der menschliche Denkapparat kann sich normalerweise unter dem Vielfachen eher etwas vorstellen als unter einem Bruchteil), und in der Legende müsste es entsprechend heißen: "versch. : gesamt". Und die Beschreibung des Graphen in meinem letzten Posting war auch falsch. Ich habe das korrigiert, bitte um Entschuldigung und gelobe Besserung.  Man sollte solche Texte nicht unter Zeitdruck schreiben. Man sollte solche Texte nicht unter Zeitdruck schreiben.
| nemored hat Folgendes geschrieben: | | Nett finde ich den im Screenshot eingefangenen Artikel, der bestimmt sehr repräsentativ für deutschsprachige Texte ist. |
Aber immerhin ist der Text auf deutsch (bis auf die Namen natürlich ).
Gruß
grindstone
_________________
For ein halbes Jahr wuste ich nich mahl wie man Proggramira schreibt. Jetzt bin ich einen! |
|
| Nach oben |
|
|
nemored
Anmeldungsdatum: 22.02.2007
Beiträge: 4597
Wohnort: ~/
|
| Verfasst am: 02.09.2014, 10:37 Titel: |
|
|
| Zitat: | | aber der menschliche Denkapparat kann sich normalerweise unter dem Vielfachen eher etwas vorstellen als unter einem Bruchteil |
Stimmt zwar, aber bei Prozenrangaben sieht das interessanterweise wieder anders aus. Wobei es natürlich mehr als seltsam ist zu sagen, 10.13% der Wörter sind verschieden.
_________________
Deine Chance beträgt 1:1000. Also musst du folgendes tun: Vergiss die 1000 und konzentriere dich auf die 1. |
|
| Nach oben |
|
|
grindstone
Anmeldungsdatum: 03.10.2010
Beiträge: 1211
Wohnort: Ruhrpott
|
| Verfasst am: 02.09.2014, 12:39 Titel: |
|
|
| Zitat: | | bei Prozenrangaben sieht das interessanterweise wieder anders aus |
Die Idee ist so gut, die könnte glatt von mir sein. Aber das ist ja auch so naheliegend, da bin ich gar nicht drauf gekommen.  Also: nächste Nachbesserung. Also: nächste Nachbesserung.
| Zitat: | | Wobei es natürlich mehr als seltsam ist zu sagen, 10.13% der Wörter sind verschieden. |
Nein, es muß dann heißen: Die Anzahl der unterschiedlichen Wörter ist 10.13% der Gesamtwörterzahl. Und diese Kurve hat interessanterweise den von Sebastian angenommenen Verlauf (wenn auch invertiert).
Gruß
grindstone
_________________
For ein halbes Jahr wuste ich nich mahl wie man Proggramira schreibt. Jetzt bin ich einen! |
|
| Nach oben |
|
|
grindstone
Anmeldungsdatum: 03.10.2010
Beiträge: 1211
Wohnort: Ruhrpott
|
| Verfasst am: 03.09.2014, 10:48 Titel: |
|
|
@Sebastian:
Kann man den Baum auch rückwärts durchlaufen? Wenn ich also einen Knoten mit einem .count - Wert <> 0 habe, feststellen, welches Wort bei ihm endet? Dann brauchte man beim Erstellen von Listen nicht das ganze Wort zu speichern, sondern nur den Pointer des Endknotens. Ich sehe da im Augenblick nur die Möglichkeit, jedem Knoten zusätzlich noch den Pointer seines Vorgängers mitzugeben, aber vielleicht weißt du ja einen Weg, wie es auch ohne geht.
Gruß
grindstone
_________________
For ein halbes Jahr wuste ich nich mahl wie man Proggramira schreibt. Jetzt bin ich einen! |
|
| Nach oben |
|
|
|
|
Du kannst keine Beiträge in dieses Forum schreiben.
Du kannst auf Beiträge in diesem Forum nicht antworten.
Du kannst deine Beiträge in diesem Forum nicht bearbeiten.
Du kannst deine Beiträge in diesem Forum nicht löschen.
Du kannst an Umfragen in diesem Forum nicht mitmachen.
|
|

